Note: This question is part of a series of questions that use the same answer choices. An answer choice may be correct for more than one question on the series. Each question is independent of the other questions in this series. Information
and details provided in a question apply only to that question.
You work on an OLTP database that has no memory-optimized file group defined.
You have a table names tblTransaction that is persisted on disk and contains the information described in the following table:
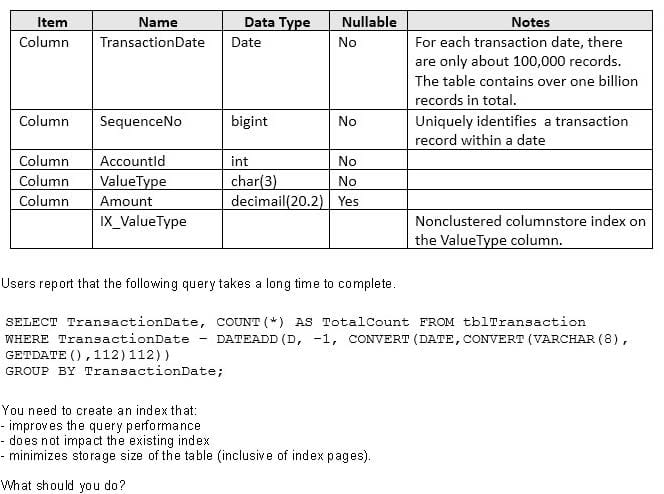
Users report that the following query takes a long time to complete.

You need to create an index that:
-improves the query performance
-does not impact the existing index
- minimizes storage size of the table (inclusive of index pages).
What should you do?
A. Create aclustered index on the table.
B. Create a nonclustered index on the table.
C. Create a nonclustered filtered index on the table.
D. Create a clustered columnstore index on the table.
E. Create a nonclustered columnstore index on the table.
F. Create a hashindex on the table.
Note: this question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in the series.
Information and details provided in a question apply only to that question.
You are developing and application to track customer sales.
You need to return the sum of orders that have been finalized, given a specified order identifier. This value will be used in other Transact-SQL statements.
You need to create a database object.
What should you create?
A. extended procedure
B. CLR procedure
C. user-defined procedure
D. DML trigger
E. scalar-valued function
F. table-valued function
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals.
You need to create a stored procedure that updates the Customer, CustomerInfo, OrderHeader, and OrderDetails tables in order.
You need to ensure that the stored procedure:
Runs within a single transaction.
Commits updates to the Customer and CustomerInfo tables regardless of the status of updates to the OrderHeader and OrderDetail tables.
Commits changes to all four tables when updates to all four tables are successful.
Solution: You create a stored procedure that includes the following Transact-SQL segment:

Does the solution meet the goal?
A. Yes
B. No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a database that is 130 GB and contains 500 million rows of data.
Granular transactions and mass batch data imports change the database frequently throughout the day. Microsoft SQL Server Reporting Services (SSRS) uses the database to generate various reports by using several filters.
You discover that some reports time out before they complete.
You need to reduce the likelihood that the reports will time out.
Solution: You partition the largest tables.
Does this meet the goal?
A. Yes
B. No
You are creating the following two stored procedures: A natively-compiled stored procedure An interpreted stored procedure that accesses both disk-based and memory-optimized tables
Both stored procedures run within transactions.
You need to ensure that cross-container transactions are possible.
Which setting or option should you use?
A. the SET TRANSACTION_READ_COMMITTED isolation level for the connection
B. the SERIALIZABLE table hint on disk-based tables
C. the SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT=ON option for the database
D. the SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT=OFF option for the database
You are developing a database reporting solution for a table that contains 900 million rows and is 103 GB.
The table is updated thousands of times a day, but data is not deleted.
The SELECT statements vary in the number of columns used and the amount of rows retrieved.
You need to reduce the amount of time it takes to retrieve data from the table. The must prevent data duplication.
Which indexing strategy should you use?
A. a nonclustered index for each column in the table
B. a clustered columnstore index for the table
C. a hash index for the table
D. a clustered index for the table and nonclustered indexes for nonkey columns
You use Microsoft SQL Server Profile to evaluate a query named Query1. The Profiler report indicates the following issues:
At each level of the query plan, a low total number of rows are processed.
The query uses many operations. This results in a high overall cost for the query.
You need to identify the information that will be useful for the optimizer.
What should you do?
A. Start a SQL Server Profiler trace for the event class Performance statistics in the Performance event category.
B. Create one Extended Events session with the sqlserver.missing_column_statistics event added.
C. Start a SQL Server Profiler trace for the event class Soft Warnings in the Errors and Warnings event category.
D. Create one Extended Events session with the sqlserver.error_reported event added.
You run the following Transact-SQL statement:

There are multiple unique OrderID values. Most of the UnitPrice values for the same OrderID are different.
You need to create a single index seek query that does not use the following operators: Nested loop Sort Key lookup
Which Transact-SQL statement should you run?
A. CREATE INDEX IX_OrderLines_1 ON OrderLines (OrderID, UnitPrice) INCLUDE (Description, Quantity)
B. CREATE INDEX IX_OrderLines_1 ON OrderLines (OrderID, UnitPrice) INCLUDE (Quantity)
C. CREATE INDEX IX_OrderLines_1 ON OrderLines (OrderID, UnitPrice, Quantity)
D. CREATE INDEX IX_OrderLines_1 ON OrderLines (UnitPrice, OrderID) INCLUDE (Description, Quantity)
Note: This question is part of a series of questions that use the same or similar answer choices. As answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a Microsoft SQL Server database named DB1 that contains the following tables:
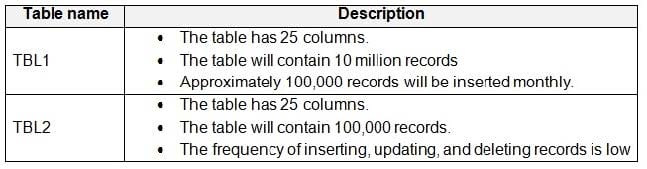
You frequently run the following queries:
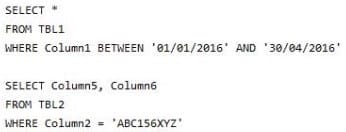
There are no foreign key relationships between TBL1 and TBL2.
You need to minimize the amount of time required for the two queries to return records from the tables.
What should you do?
A. Create clustered indexes on TBL1 and TBL2.
B. Create a clustered index on TBL1.Create a nonclustered index on TBL2 and add the most frequently queried column as included columns.
C. Create a nonclustered index on TBL2 only.
D. Create UNIQUE constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
E. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Create a nonclustered index on TBL2.
F. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Make no changes to TBL2.
G. Create CHECK constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
H. Create an indexed view that combines columns from TBL1 and TBL2.
Note: This question is part of a series of questions that use the same or similar answer choices. As answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a Microsoft SQL Server database named DB1 that contains the following tables:
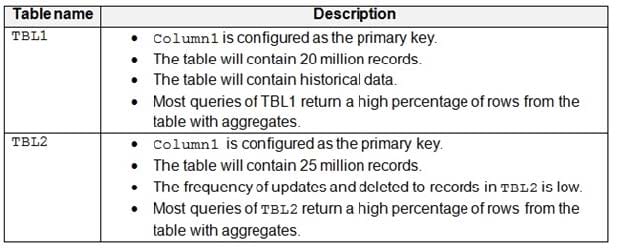
There are no foreign key relationships between TBL1 and TBL2.
You need to minimize the amount of time required for queries that use data from TBL1 and TBL2 to return data.
What should you do?
A. Create clustered indexes on TBL1 and TBL2.
B. Create a clustered index on TBL1.Create a nonclustered index on TBL2 and add the most frequently queried column as included columns.
C. Create a nonclustered index on TBL2 only.
D. Create UNIQUE constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
E. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Create a nonclustered index on TBL2.
F. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Make no changes to TBL2.
G. Create CHECK constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
H. Create an indexed view that combines columns from TBL1 and TBL2.
